IO
Interaction Design / Creative Coding / Machine Learning
Visualizing Semantic Audio Pt 1
"Walk so silently that the bottoms of your feet become ears"
- Pauline Oliveros
Listening
The act of listening has multiple connotations: perceiving waves of sounds, staying quiet, or giving active, focused attention to something. Moreover, giving attention means interpreting and understanding the object. Going further on this line: I think, listening is the practice of distinguish between signal and noise, aka extracting meaningful components from an undefined, unpredictable mass and transform those components into meaningful representations. Semantic audio means when labels are provided to refer to meaningful (semantic) components in a sound.
Extracting useful features is a key concept in understanding an inner representation of a phenomena. The act of listening is so deeply combined with language that usually it's hard to distinguish between the two: we construct and inherit the concept of our reality through language.
If we extend the concept of language, we can leave behind natural spoken languages and artificial combinatory languages. Language is a complex representation constructed from simple set of rules and their combination. Moreover, language is referring to the cognitive state of its users and creators which is not a logical, discretely computable binary representation. Instead, it is full of subjective, unquantifiable bifurcations and their constellations which can not be understood by just examining the structure that describes them. However if you are interested in how regular text or other data translates to binary representation, you can try with this online translator, by ConvertBinary.
Every formalizable system that is used for communication can be considered as language. Speaking, music, drawings, interstellar messages, colours of a cephalopod, everything.
Machine Listening: an expriment
There are a few methods that can be used for understanding audio. Extracting and classifying the provided semantic components involve a special field of machine learning, namely machine listening. Extracting information does not require the reconstruction of waveforms, it can be realized also through different types of "fingerprints" of the signal, think of Shazam as a great example in product.
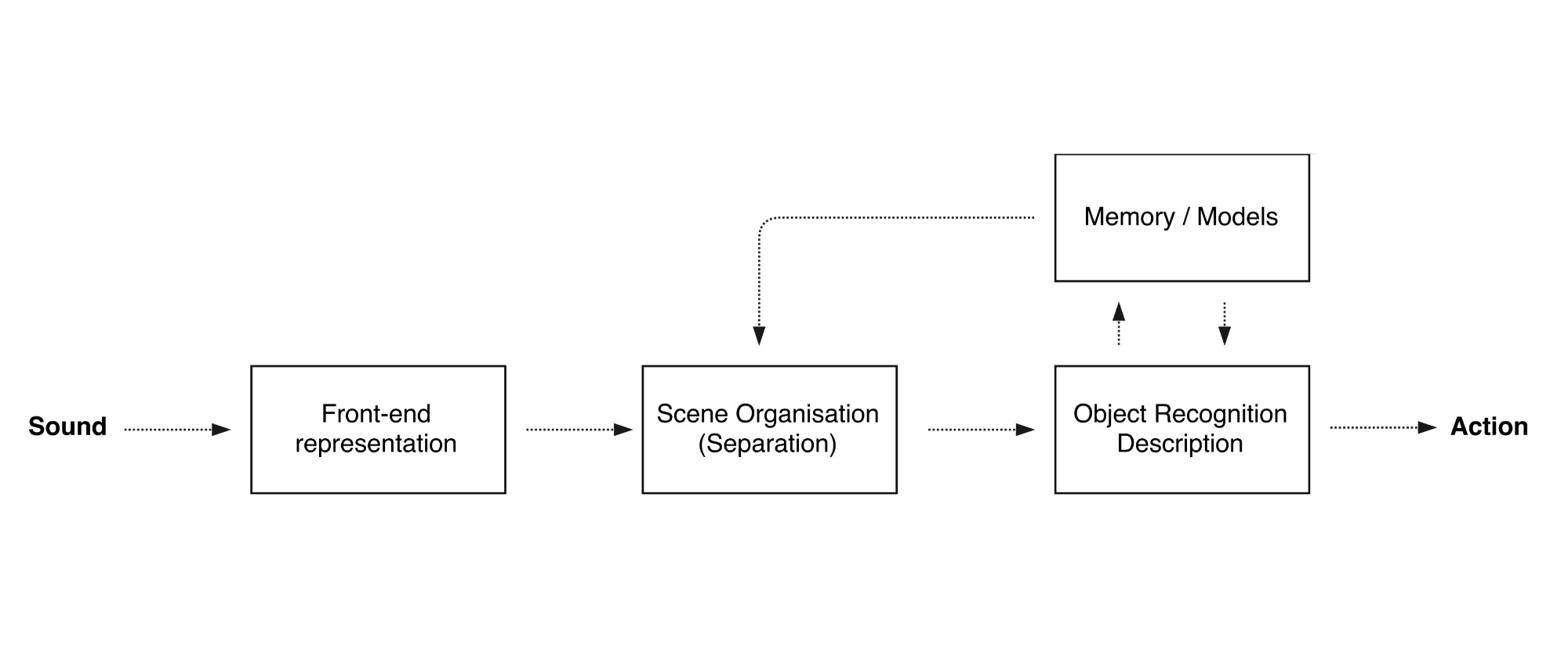
Basic steps of a machine listening process
With the help of different creative coding tools & frameworks, it is possible for artists and curious hackers to experiment with these methods in relatively simple and intuitive ways. For this particular experiment for classification, I am extracting features by using the Mel Frequency Cepstrum Coefficients of the sounds (this technique is used for speech recognition, formants, differing aspects of spoken syllables can be separated quite easily with the method). Then, I record particular pieces from the sound source that I will want to visualize. Those snippets are considered as different classes for the listening system.
When collected all the accurately segmented data I train the system to try to predict the class of any incoming sound. The classification algorithm is trying to guess from the sound stream, it gives ranks for each class, so it is possible to predict the amount of likeliness of each of them at any time. The weight of that likeliness is used for the visualization. The current learning algorithm is Naive Bayes, but I plan to make a more detailed comparision between algorithm accuracies in a later post.
Visualization
An interesting aspect of the system I started to develop is about predicting patterns: if the system thinks it is hearing sound chunk "A" then it is showing the visual representation of label "A" (a colour in this case). If it thinks that this example might more like "B", then it shows the color assotiated with class "B". The result is highly subjective, depending on the selected examples to train with, and the pairing process of visual symbols, colors or other representation to audio textures and characteristics. The colors of labels (and their prediction rank) are displayed as bars on the left in the videos. As a possible outcome, this type of visualization can give a hint on semantic contents, assotiations and metaphores (based on internal representations) instead of regular visualization techniques that are relying on pure physical aspects and mapping strategies.
Visualization examples: sound of walking (source: freesound), custom
synthesis (self made), and a piano (source: freesound)
Visualizing realtime sound is a special case of data representation: there is only momentum and past elements, we can't predict what comes next. It is a highly descriptive (as opposed to prescriptive) process. This momentum should describe the structure of sound in an objective way (a reduced spectra is more than good for that). It also needs to maintain some previous states of the sound in order to perceive and compare changes over time, such as cycles and rhythm. For this, I rotated time axis around into a circular form, where newly recognised components (above a certain volume threshold) are travelling over this line and fade away along with the passing time. This technique allows watching micro-temporality instead of the well known macrotemporal timeline concepts of notation systems. The dimensions of the representation is constructed along the following axes:
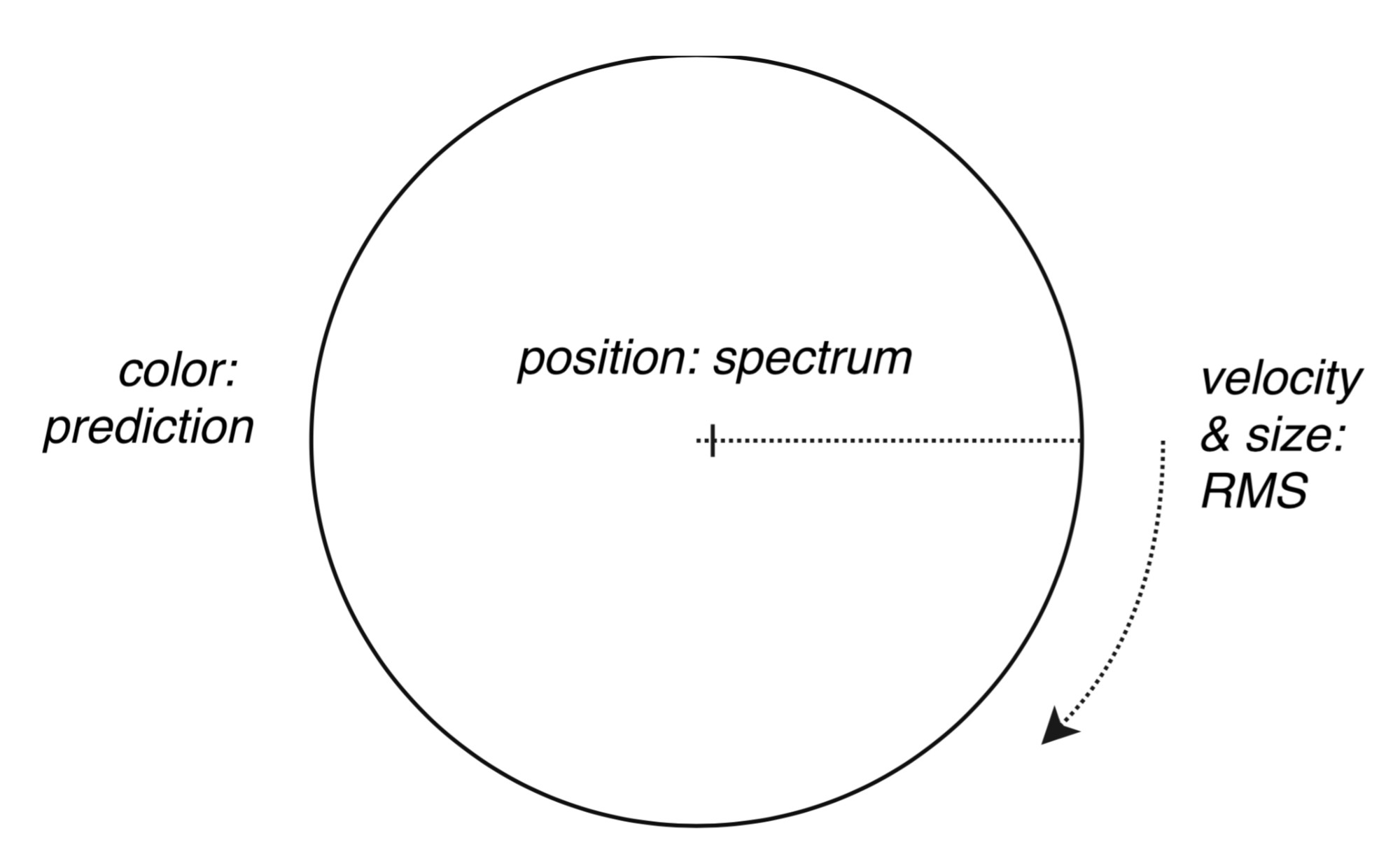
Simplified diagram of the sound visualization
structure that can be seen in the videos
Audio feature extraction (mfcc, spectrum & rms) is made with ofxMaxim, the training and classification is made with the Openframeworks port of Gesture Recognition Tool. Source will be available as soon as I succeed in generalizing the code into a more usable, flexible form.