IO
Interaction Design / Creative Coding / Machine Learning
Why Tweaking Matters
As it turned out in the last post, machine listening has a few key components, which starts with finding good features. The most sensitive psychoacoustic elements for human speech are falling into just a few parts of the audible spectrum. Usually, the Mel Frequency Cepstrum (MFCC) extraction is used for determine a handful set of those components. Since I couldn't find a simple and good way to extract these features from the audio within PureData vanilla, I headed up to a paper that describes how to build one in C, and turn it into a Pure Data extension. For OSX I compiled the [MFCC~] external using pd-lib-builder, a beautiful, streamlined and handy cross platform library builder template. Since custom built externals can be added to libPd projects, these methods can be embedded easily into any applications that run everywhere, from linux ARM to iOS devices.
Understanding your data
For interpreting and bringing data into meaningful context, dimension reduction is needed. In fact, MFCC itself is a special dimension reduction from a high dimensional spectral data into a few dimensional vector elements. For the experiment, I am using 13 bands of Mel Frequency data, aka the dimensionality is reduced from 1024 (original spectral bins) to 13 meaningful (at least from the point of human hearing condition) elements. This feature vector is then reduced into 5 discrete elements, using a Support Vector Machine classification algorithm. This is a well known method that consists of supervised learning models with associated learning algorithms that analyze data and recognize patterns, used for classification and regression analysis. Given a set of training examples, each marked as belonging to one of two categories, an SVM training algorithm builds a model that assigns new examples into one category or the other, making it a non-probabilistic binary linear classifier.
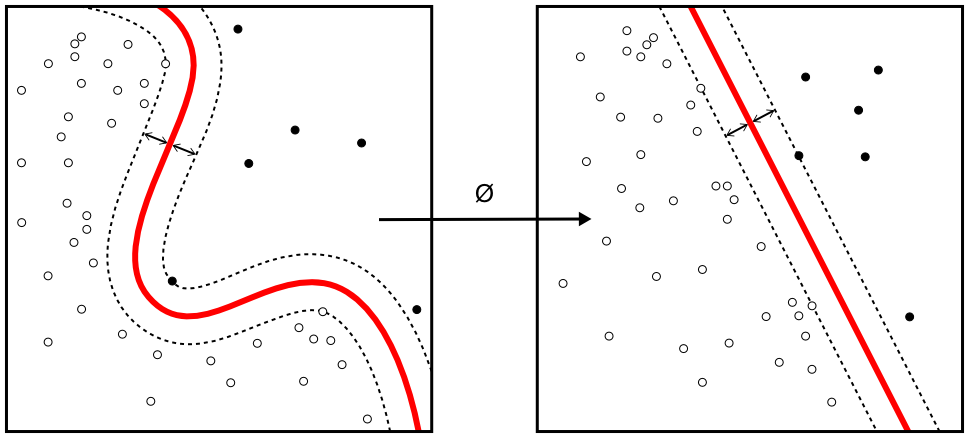
Input Space (left) and Feature Space (right): Rearranged, using a set of mathematical functions, known as kernels. The process of rearranging the objects is known as mapping (transformation). Note that in this new setting, the mapped objects (right side of the schematic) is linearly separable and, thus, instead of constructing the complex curve (left schematic), all we have to do is to find an optimal line that can separate the empty and filled objects. source
{kind=link}
An SVM model is a representation of the examples as points in space, mapped so that the examples of the separate categories are divided by a clear gap that is as wide as possible. New examples are then mapped into that same space and predicted to belong to a category based on which side of the gap they fall on. For the experiment, I'm using the ml-lib library for Pure Data & Max, that is built on top of Nick Gillian's Gesture Recognition Toolkit I was using for many other experiments within other coding frameworks. SVM is implemented within the [ml.svm] object, including learning, training and predicting procedures using Pd's messaging system that makes rapid prototyping a very fast & easy task. The video below illustrates how simple it is to teach some spoken syllables to the system, and then, trying to predict new instances from the audio stream.
Audio feature extraction (using mfcc), classification (using ml-lib) built within Pure Data (predictions are displayed on the bottom-left of the patch)
Why tweaking matters
The other day, some scientists succeeded in classifying communication signals of 22 Egyptian fruit bats (Rousettus aegyptiacus), by observing their behaviours for 75 days. The scientists applied a modified speech recognition machine learning algorithm to classify their conversations. They fed 15,000 calls into the software. They then analyzed the corresponding video to see if they could match the calls to certain activities. At the end, it turned out, that 60 percent of their signals (which were initially thought of as random signals) can be classified into four types: arguing about food, dispute about their positions within the sleeping cluster, unwanted mating advances and argues with another bat sitting too close. Moreover, they treat each other as individuals (altering signals regarding to whom they are sending the message), which is very rare between nonhuman species. They used modified speech recognition systems (based on MFCC, originally developed for humans) for feature extraction and Gaussian Mixture Model for classificating the signals.
Why I think these news are important is, that it turns out that understanding nonhuman intelligence, even with the case of other familiar species around us, involves such sophisticated technology. Why not imagine this type of research & communication in an extraterrestrial context? It appears to be evident that interpreting foreign, cross-dimensional languages and messages should also involve some type of similar "meta-interpretive" technology that we find today in different branches of Machine Learning. As Paul Davies points out in his book Eerie Silence, "if we ever encounter extraterrestrial intelligence, I believe it is very likely to be postbiological in nature."