IO
Interaction Design / Creative Coding / Machine Learning
Visualizing Semantic Audio Pt 2
This post is focusing on the comparison of different supervised learning algorithms in a more real-world scenario, as a continuation of a previous post that was trying to sum up a bit the different branches of ML techniques that can be useful in realtime interactions. This scenario targets a specific area: machine listening and visualization.
Previously I proposed ways to visually represent quasi-real time data, specifically microtemporal events in the audio. Since temporality and order matters within audio signals, change is really important to indicate in order to compare the actual state to the previous state.
This next proposal focuses on visualizing semantic components of audio in a macrotemporal scale, which involves some kind of timeline, where the whole structure of time becomes visible at a glance. So, x-axis will be time, just as with any sequencer or editor program. However, the different semantic components will take their position on the y-axis. To make things visually more separated, each symbol (aka class) has its own color. Moreover, each class prediction has a confidence guessed by the underlying algorithm, that is indicated by the vertical size of each class component. If it is high (close to 1), the system is very sure about that it recognizes that specific class and it becomes clear on the visualization, since the range of the drawn class will be wider. If it is less, the chance of being heard that symbol is very low, the drawing is thinner. Very low predictions (unneeded noise below confidence of 0.1) are filtered out.
The sound file being analysed is a field recording taken from freesound. Segmentation (selecting audio snippets to teach) is made by hand as you see on the video. The features extracted from the audio are the first 13 bands of MFCC components, so the system is trained on a 13 dimensional feature space. Each class takes samples from less than a second long audio. As you see, 2-3 examples are added to the model per class. Class colors:
- Pink >> background noise (fading out around half time)
- Blue >> cars passing by
- Red >> hitting construction materials
- Black >> human speech fragments
- White >> bird singing
The following images are the results of different supervised learning algorithms listening over the whole soundfile, trying to guess what they hear. Please note, it is a very specific case, so the test does not mean that one algorithm is better or worse than another. The experiment highlights the nature of different methods regarding to these certain number of features, length of data and desired output.
Adaboost
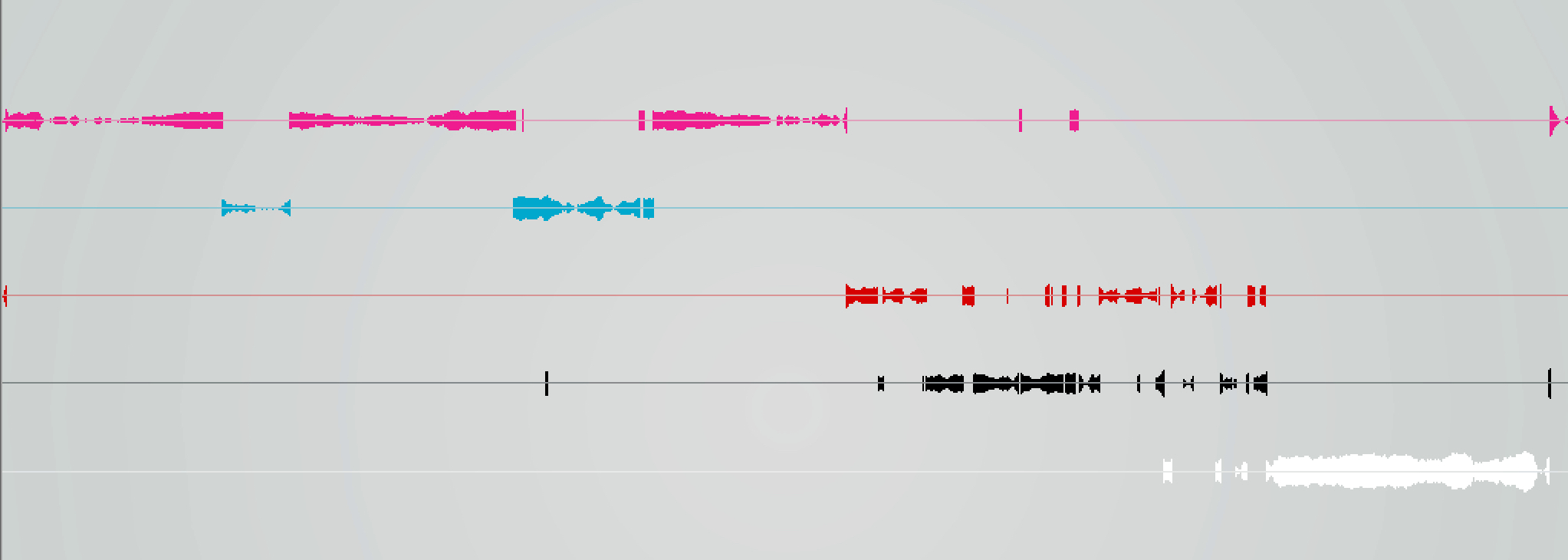
The results are quiet noisy, and the confidence level always remain low.
Decision Tree
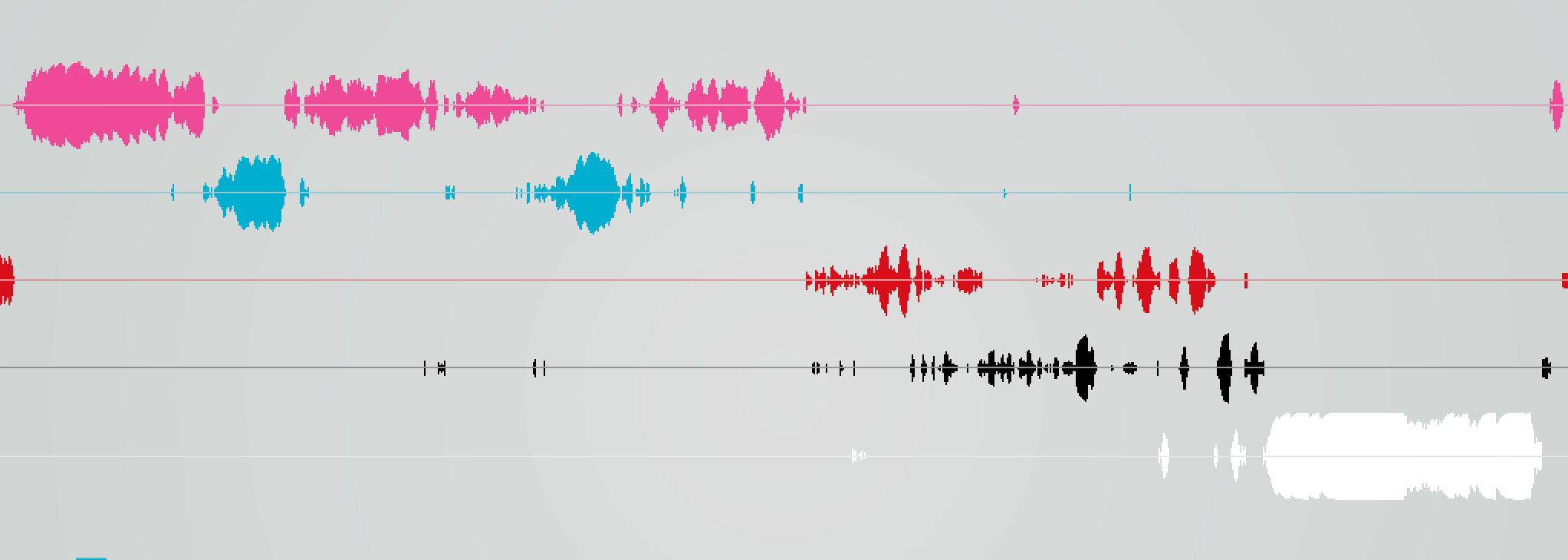
Noisy, the first two classes are mixed and misunderstood very often. The class of human speech is recognized too much, whereas it is not present at every moment on the original recording.
K-Nearest Neighbour
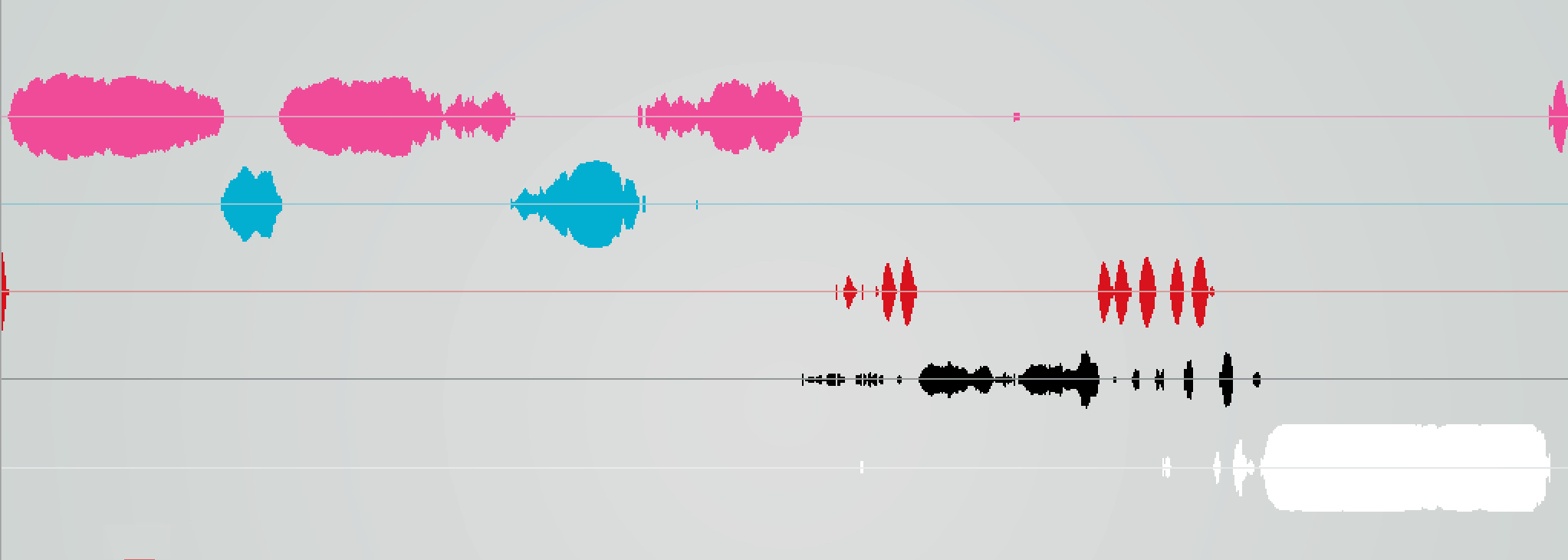
Much better than the previous examples, there is a very high confidence value for the prediction, almost without noise.
Mindist
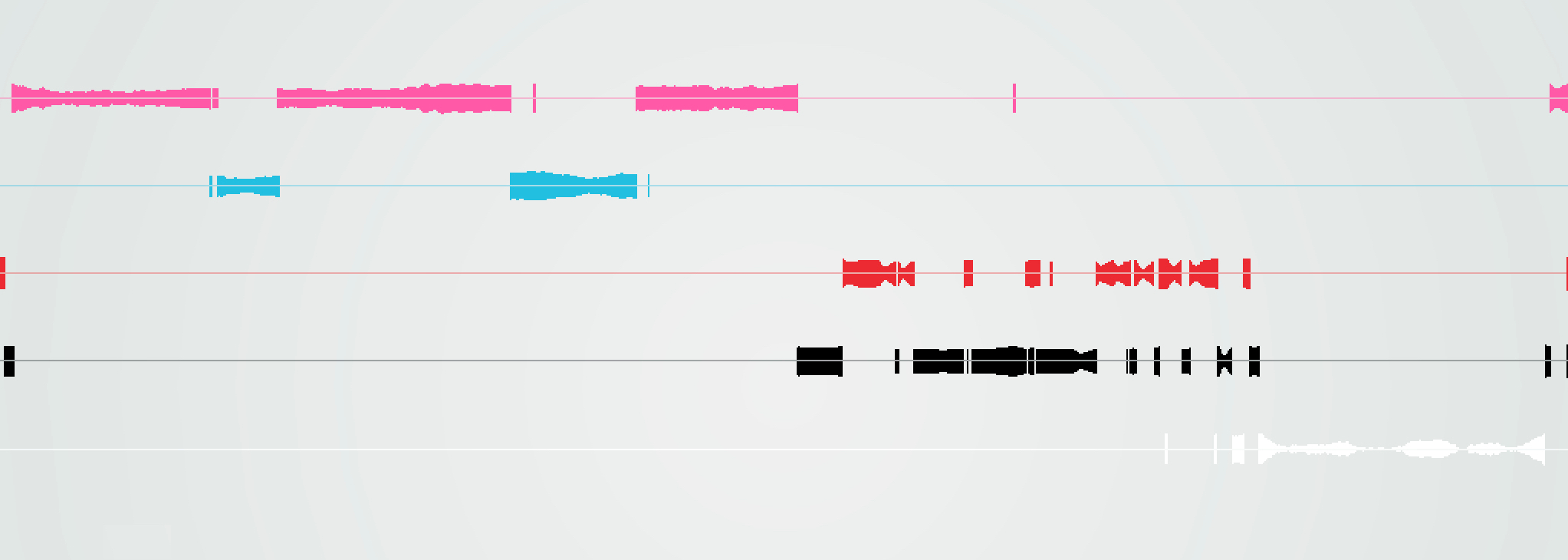
Worse than all the above. It acts as it had a two state thresholding behaviour, its confidence value is useless.
Naive Bayes

Works quite well, however more noisy than the K-Nearest Neighbour.
Random Forest
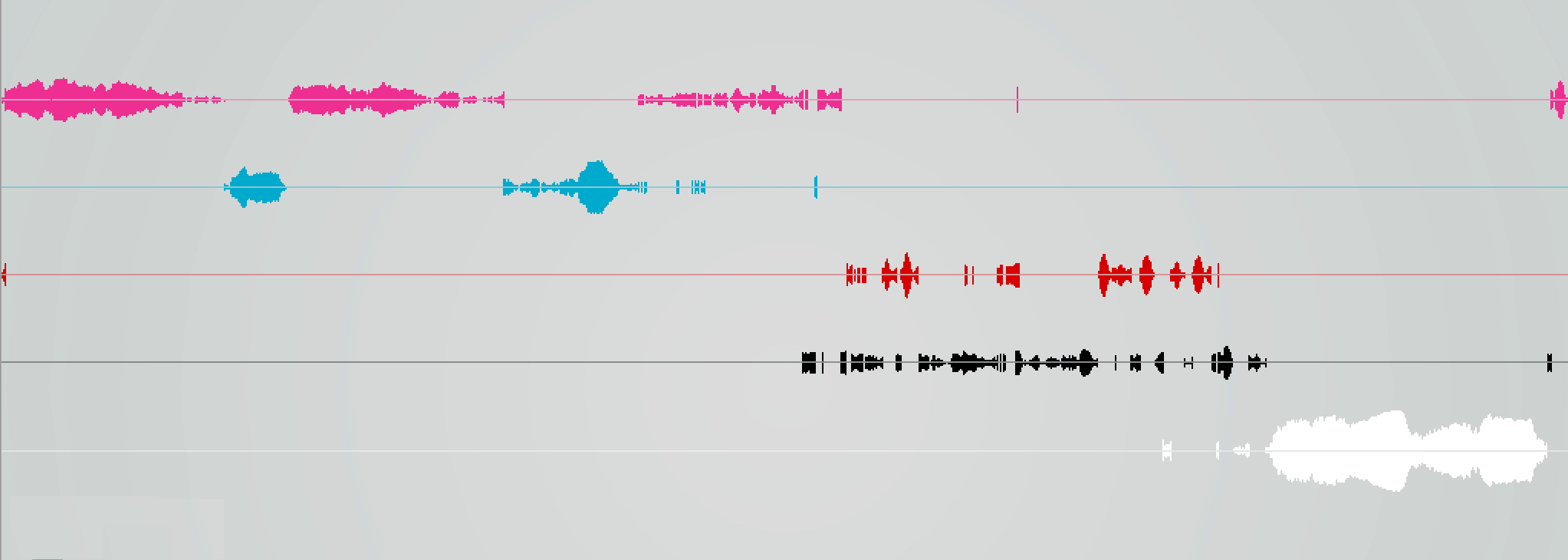
Less noise, also it has less confidence values.
Gaussian Mixture Model
I was not able to test GMM with 13 feature vectors.
Softmax

The worst result of all within this experiment. It is very noisy, the "car" class is hallucinated everywhere, "human speech" class is not recognized at all.
Support Vector Machine

The winner for this task: very high confidence value where increasing and decreasing of its curve is as clean as with a pre-defined ADSR envelope. There is no noise.
These examples are made for audio, but there is an intention to make a tool that helps in the selection process of realtime data classification in a visual way. Beyond audio, different type of data sources and algorithms can also be visualized this way. It can be useful for generic classification tasks, such as training, calibration, data forensics. Building realtime interactions, fine tuning of gesture recognition with devices like Leap Motion, Project Soli can also benefit from such techniques.